IA, redes neurais e reconhecimento de texto escrito à mão
A IA está transformando nossa compreensão de como as pessoas escrevem e levando a tecnologia de texto escrito à mão digital a novos patamares
A importância da IA
IA é abreviação de inteligência artificial. Ela se refere ao campo da ciência da computação envolvido na criação de máquinas inteligentes que podem reproduzir e aprimorar certas capacidades do cérebro humano, como leitura, compreensão ou análise.
IA na MyScript
Nossos principais produtos de software têm tecnologia de IA proprietária. Usamos a IA para interpretar conteúdo escrito à mão em mais de 70 idiomas, analisar a estrutura de notas escritas à mão, entender equações matemáticas e até mesmo reconhecer e converter notações musicais desenhadas à mão.
Nossa tecnologia é amparada por mais de 20 anos de pesquisa e desenvolvimento. Para criar o mecanismo de reconhecimento de texto escrito à mão mais preciso do mundo, realizamos (e seguimos realizando) pesquisas contínuas sobre as minúcias da formação da linguagem: como as frases são construídas a partir de palavras e as palavras a partir de caracteres; como os sinais diacríticos são colocados acima ou abaixo de certas vogais, e assim por diante.
Na MyScript, vários grupos de pesquisadores colaboram para criar e desenvolver o melhor sistema da categoria, capaz de compreender uma variedade notável de conteúdo escrito à mão.
Pesquisa de texto escrito à mão
Nossa equipe de pesquisa de texto escrito à mão usa técnicas de aprendizado de máquina para resolver problemas que podem ser formulados como problemas de conversão de sequência-para-sequência (do inglês sequence-to-sequence, ou seq2seq), como ao converter texto escrito à mão em seus caracteres constituintes.
As técnicas devem ser adaptadas a diferentes alfabetos e convenções, para permitir o reconhecimento de, por exemplo, idiomas da direita para a esquerda como árabe ou hebraico, vogais diacríticas em manuscritos indianos, ideogramas chineses, o alfabeto coreano Hangul ou caracteres japoneses Hiragana, Katakana ou Kanji sequenciados verticalmente.
Pesquisa de texto escrito à mão 2D
Essa equipe cria modelos matemáticos baseados em gramáticas e/ou analisadores bidimensionais. Eles abordam problemas que não podem ser resolvidos por abordagens seq2seq, como o reconhecimento de expressões matemáticas, notação musical ou diagramas e gráficos. Eles empregam técnicas baseadas em gráficos para permitir o reconhecimento, com o grande desafio do processamento em tempo real.
Pesquisa de processamento de linguagem natural
Nossa equipe de processamento de linguagem natural desenvolve algoritmos que podem entender idiomas tão naturalmente quanto qualquer ser humano. A equipe usa corpora textuais contendo centenas de milhões de palavras obtidas de artigos e documentos disponíveis publicamente. A partir deles, a equipe cria vocabulários linguísticos, elabora modelos para prever o próximo caractere em uma frase e projeta sistemas que identificam e corrigem erros ortográficos.
Coleta de dados
Grande parte do nosso trabalho é possível graças a dados de amostra anônimos compartilhados conosco voluntariamente por usuários de todo o mundo. Essas "amostras de treinamento" (como são conhecidas na pesquisa de IA) são sempre tratadas com o maior respeito à privacidade e segurança e são um grande trunfo para a empresa, ajudando-nos a refinar e aprimorar nossa tecnologia.

Reconhecimento de texto escrito à mão: os desafios
O reconhecimento de texto escrito à mão apresenta desafios técnicos significativos devido à enorme variabilidade de estilos de texto manuscrito. Fatores como idade do escritor, lateralidade, país de origem e até mesmo a superfície de escrita podem afetar a escrita produzida – e isso antes de considerar os efeitos de diferentes idiomas e alfabetos.
Para ilustrar os desafios envolvidos: um bom software de reconhecimento de texto escrito à mão deve ser capaz de distinguir um único caractere chinês dentre mais de 30.000 ideogramas possíveis. Ele também deve ser capaz de reconhecer e decodificar a escrita bidirecional para que possa continuar funcionando quando um escritor que usa um idioma escrito da direita para a esquerda (como árabe ou hebraico) inclui várias palavras estrangeiras da esquerda para a direita em seu conteúdo.
A escrita à mão cursiva torna ainda mais difícil para o software segmentar e reconhecer caracteres individuais, enquanto traços atrasados (como sinais diacríticos inseridos no término da escrita da palavra) oferecem mais oportunidades para confusão. Os layouts não estruturados comuns a essas notas tornam a análise de conteúdo automatizada muito mais complicada, assim como a inclusão de outros tipos de conteúdo, como expressões matemáticas, gráficos e tabelas.
O tempo também é um fator: o software de reconhecimento de texto escrito à mão deve funcionar em tempo real, interpretando as entradas do usuário enquanto ele escreve. Se o usuário editar seu conteúdo enquanto escreve, por exemplo, riscando uma palavra para apagá-la, inserindo um espaço ou movendo um parágrafo, o mecanismo de reconhecimento deve ser capaz de acompanhar.
Além disso, a tecnologia de reconhecimento de texto escrito à mão deve ser capaz de analisar caracteres tipográficos, bem como traços manuscritos, para que um usuário possa importar texto digitado de páginas da web ou outros aplicativos e, em seguida, adicionar anotações nele manualmente, quando necessário. Um bom mecanismo de reconhecimento deve interpretar essas interações complexas com precisão, diferenciando entre gestos de edição, adição de sinais diacríticos ou a escrita de novos caracteres e palavras.
Investindo em redes neurais
Mais de 20 anos atrás, quando a comunidade global de pesquisa de reconhecimento de texto escrito à mão estava concentrando seus esforços nos modelos ocultos de Markov (HMM) e nas máquinas de vetores de suporte (SVM), a MyScript seguiu um caminho diferente.
Em vez disso, decidimos nos concentrar em redes neurais.
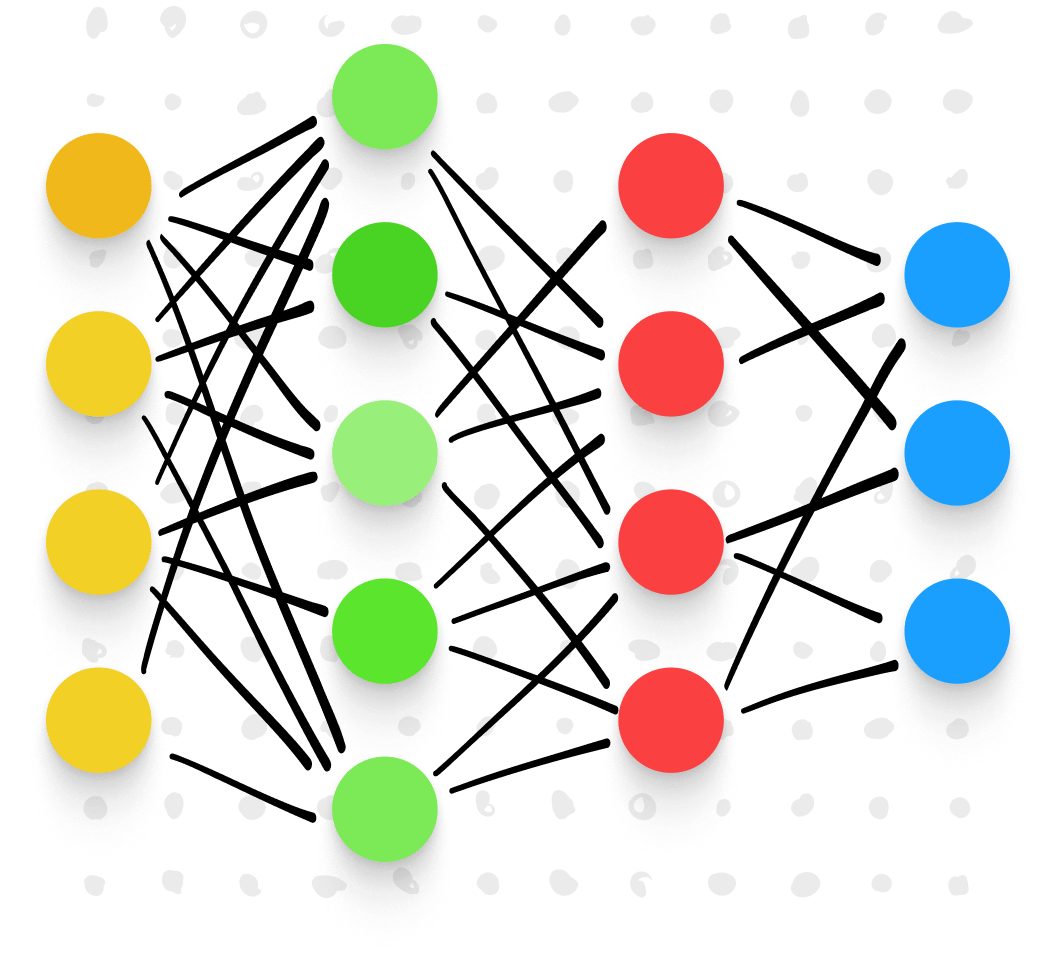
Uma rede neural é um tipo de aprendizado de máquina que imita os processos de aprendizado do cérebro humano. Orientada por algoritmos avançados, uma rede neural identifica padrões em conjuntos de dados vastos, permitindo generalizações mais precisas sobre o que estivermos estudando, por exemplo, texto escrito à mão.
As redes neurais são construídas a partir de modelos matemáticos "treinados" para identificar padrões de acordo com variáveis predeterminadas, ou "dimensões". Algoritmos cuidadosamente programados dividem e classificam de modo repetido os dados de acordo com essas dimensões, classificando e reclassificando até que surjam padrões claros.
Dessa forma, as redes neurais podem realizar tarefas que seriam impossíveis para humanos. Elas vasculham quantidades de dados enormes em alta velocidade, destacando padrões que, de outro modo, podem passar despercebidos. Acreditávamos que poderíamos usar as redes neurais para treinar o mecanismo de reconhecimento de texto escrito à mão mais preciso e avançado já visto no mundo.
Usando redes neurais para reconhecer texto escrito à mão
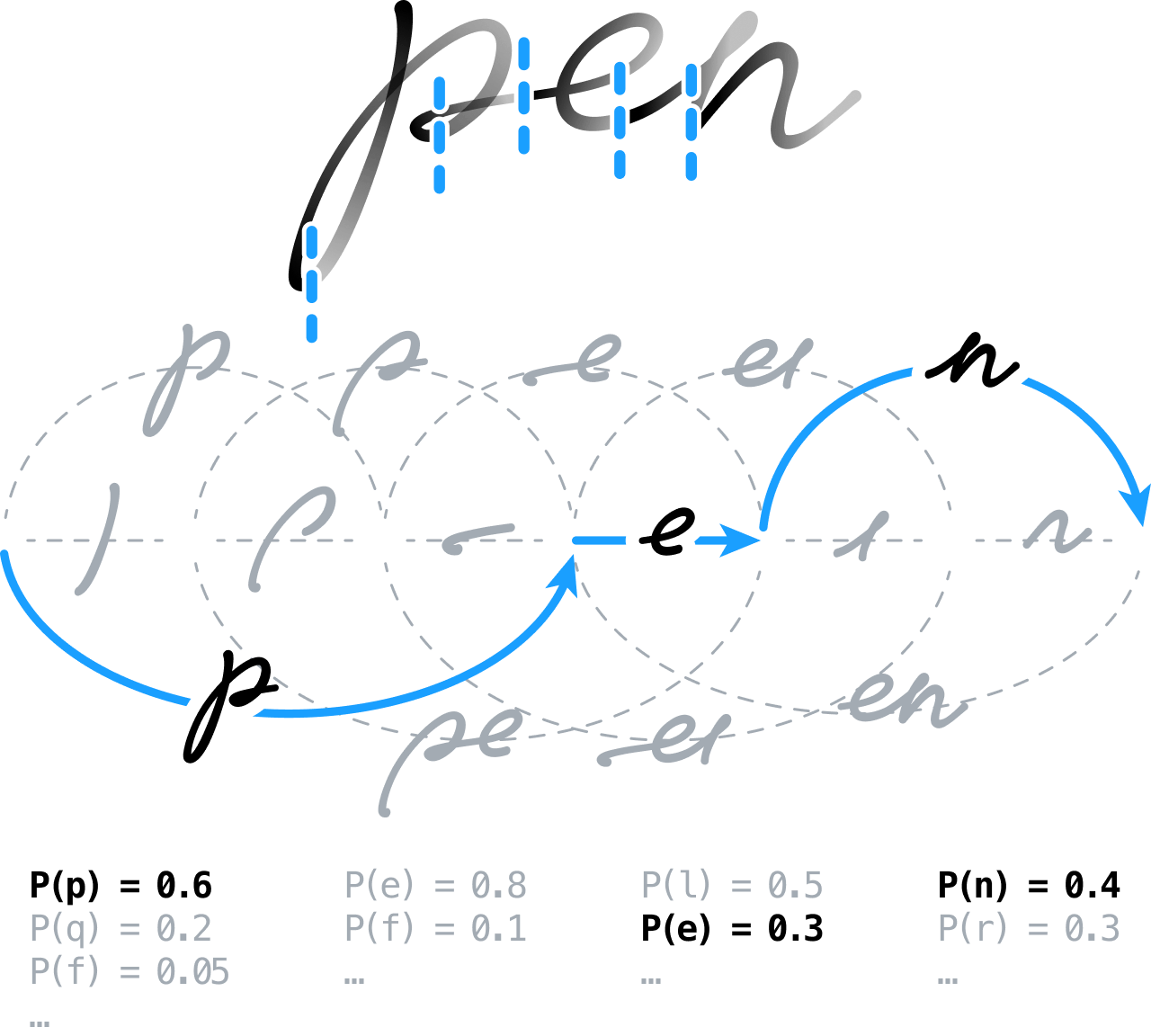
Desde o início, nossa ideia era pré-processar o conteúdo manuscrito a fim de prepará-lo para análise, realizando tarefas como extrair linhas, normalizar a tinta e corrigir qualquer inclinação. Em seguida, dividiríamos o sinal em muitos segmentos e deixaríamos o mecanismo de reconhecimento decidir a posição dos limites entre caracteres e palavras posteriormente.
Isso significava construir um gráfico de segmentação, modelando todas as segmentações possíveis – efetivamente, agrupando segmentos contíguos em hipóteses de caracteres que eram então classificadas por meio de redes neurais feedforward (alimentadas para a frente). Usamos uma nova abordagem baseada em um esquema de treinamento discriminativo global. Hoje em dia, essa técnica é bastante empregada na estrutura de classificação temporal conexionista (CTC) para treinar sistemas neurais de sequência-para-sequência (seq2seq).
Também criamos e empregamos um modelo de linguagem estatística de última geração, incorporando informações lexicais, gramaticais e semânticas que poderiam ser usadas para esclarecer e resolver algumas das ambiguidades restantes entre diferentes candidatos a caracteres.

Treinamento de IA para linguagens 2D
Nosso sucesso com as redes neurais nos permitiu criar o melhor mecanismo de reconhecimento de texto escrito à mão do mundo para manuscritos impressos e cursivos. Mas alguns idiomas oferecem uma complexidade ainda maior, o que levou ao nosso próximo desafio.
Reconhecimento de caracteres chineses
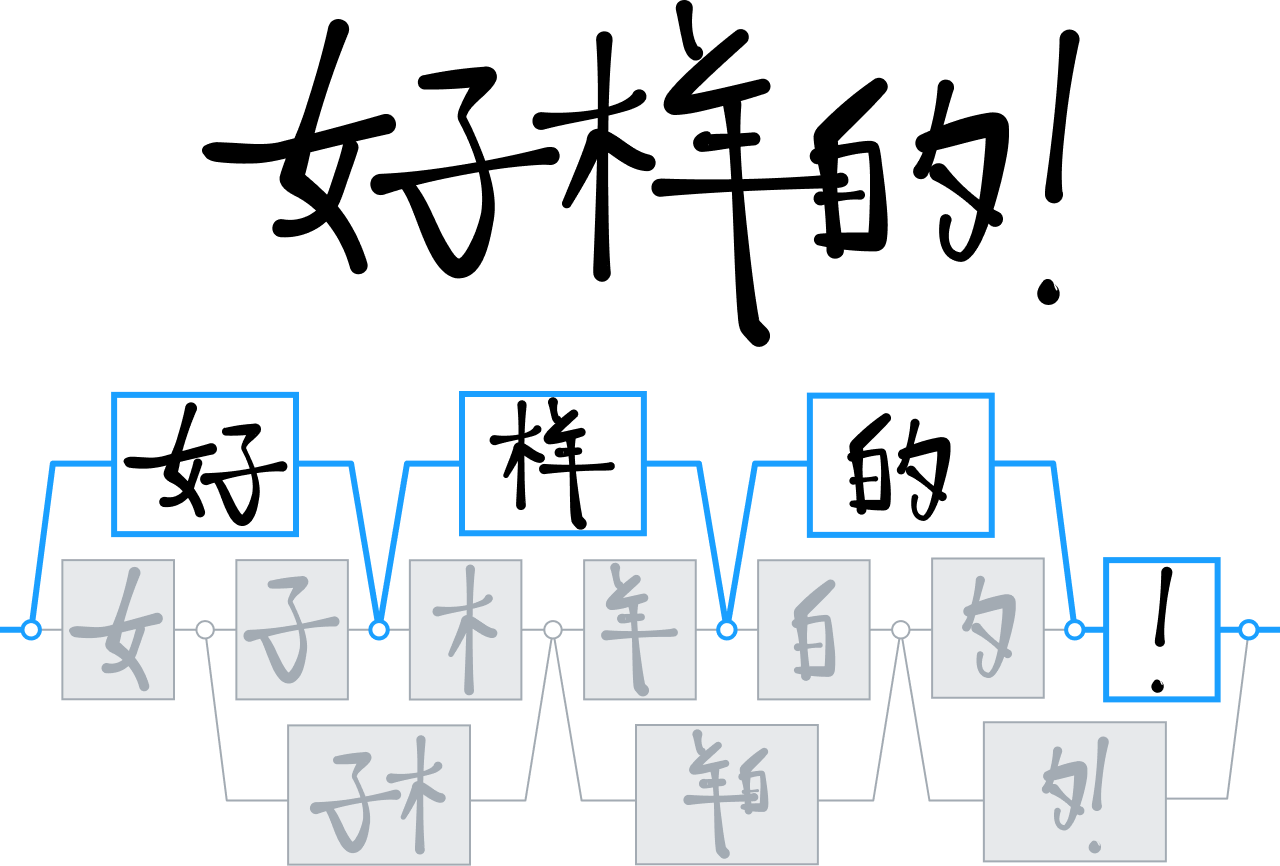
Ao longo dos anos, a MyScript desenvolveu uma série de tecnologias para analisar e interpretar linguagens bidimensionais, em especial ideogramas chineses.
Enquanto a maioria dos concorrentes do setor estava usando técnicas de árvore de decisão para diferenciar e interpretar caracteres chineses, nós apostamos nas redes neurais, treinando nosso mecanismo para reconhecer mais de 30.000 ideogramas.
Foi a primeira vez que uma equipe de pesquisa treinou com sucesso uma rede tão grande, algo possibilitado por uma enorme campanha de coleta de dados que resultou no maior conjunto de dados de caracteres chineses manuscritos já visto.
Usamos esses dados para desenvolver uma nova arquitetura neural que explora especificamente a estrutura dos caracteres chineses. Também integramos uma técnica de agrupamento especializada para acelerar os tempos de processamento. Essas inovações nos permitiram oferecer um novo nível de reconhecimento de escrita à mão a um mercado no qual a entrada por teclado permanece extremamente difícil e inflexível. Elas também nos permitiram adicionar o mesmo nível de suporte para outros idiomas, como japonês, híndi e coreano.
Reconhecimento matemático
Após termos empregado com sucesso as redes neurais para analisar e reconhecer uma variedade de idiomas do mundo, um novo objetivo surgiu: o reconhecimento de expressões matemáticas.
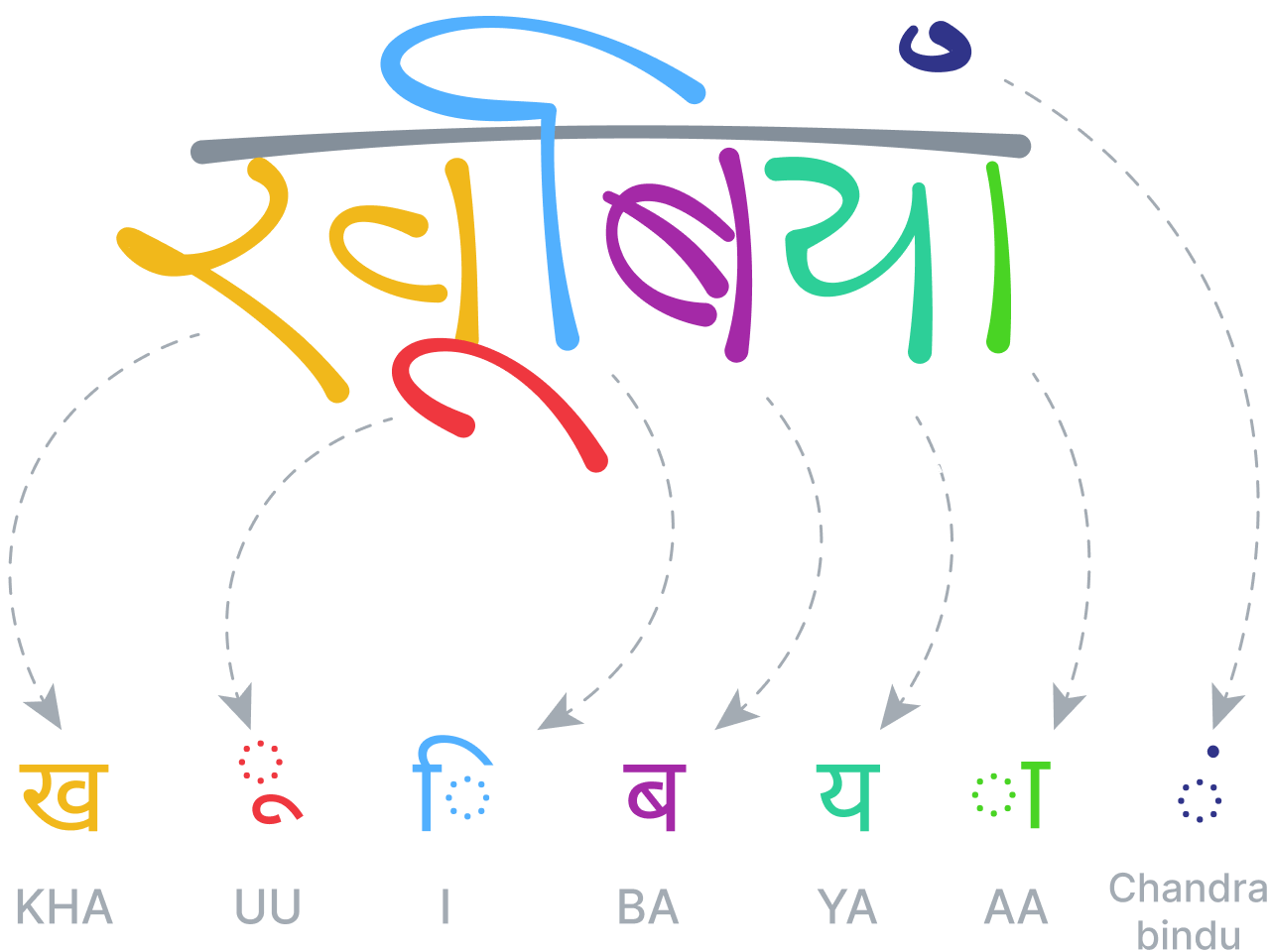
Enquanto as linguagens regulares possuem sequências estruturais de caracteres e palavras, as linguagens bidimensionais (ou visuais) geralmente são mais bem descritas por uma estrutura de árvore ou gráfico, com relações espaciais entre os nós. Assim como acontece com o texto, nosso sistema de reconhecimento matemático é construído com base no princípio de que segmentação, reconhecimento, análise gramatical e semântica devem ser tratados simultaneamente e no mesmo nível, para produzir os melhores candidatos ao reconhecimento.
O sistema analisa as relações espaciais entre todas as partes de uma equação matemática, de acordo com as regras estabelecidas em sua gramática específica e especializada e, em seguida, usa essa análise para determinar a segmentação. A gramática em si compreende um conjunto de regras que descrevem como analisar uma equação, onde cada regra está associada a uma relação espacial específica. Por exemplo, uma regra de fração define uma relação vertical entre um numerador, uma barra de fração e um denominador.
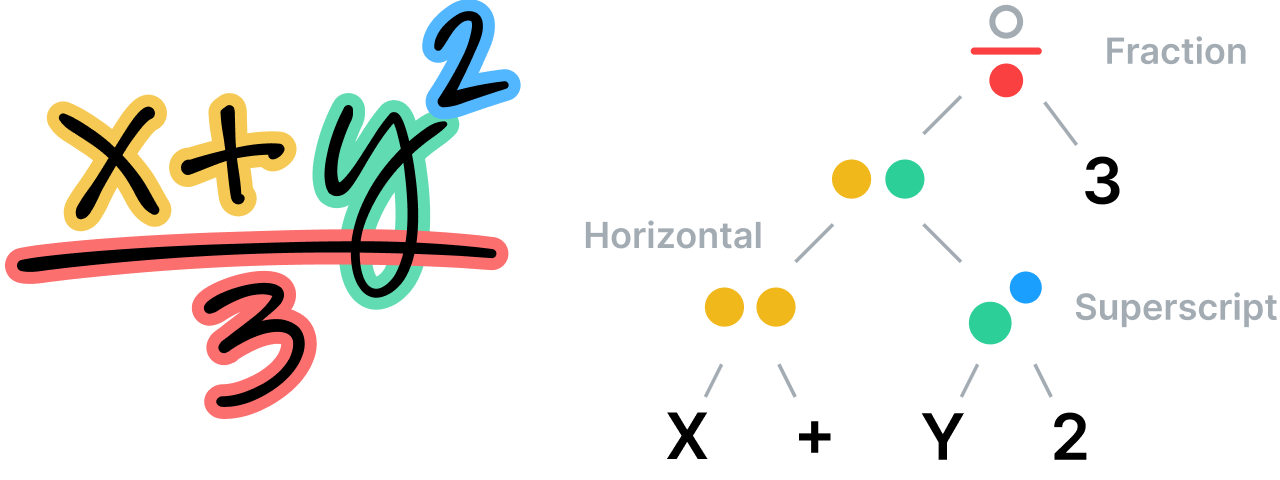
Entendendo notas não estruturadas
O reconhecimento preciso e imediato de expressões matemáticas abriu novas possibilidades ligadas ao layout e conteúdo das notas manuscritas.
Se nosso mecanismo de reconhecimento pudesse interpretar corretamente as relações espaciais entre partes de equações matemáticas, ele também poderia identificar com precisão tipos de conteúdo não textual? Nesse caso, poderíamos começar a superar os problemas apresentados por notas não estruturadas, usando nossa tecnologia para identificar com precisão e, até mesmo, embelezar elementos como diagramas desenhados à mão.
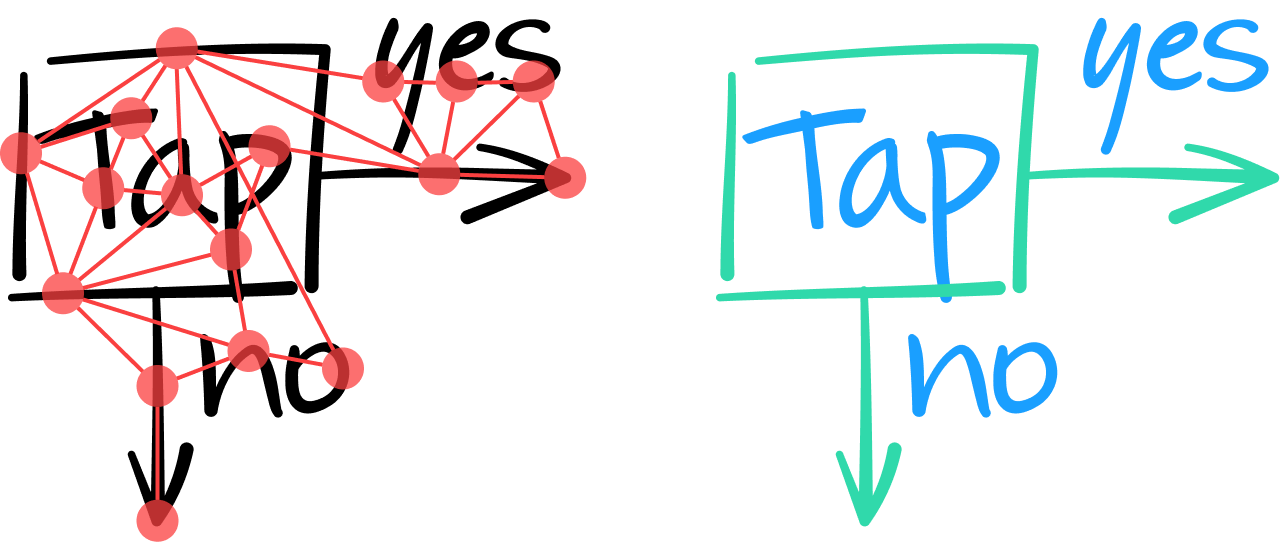
Acreditamos que as arquiteturas de redes neurais baseadas em gráficos (GNN) eram adequadas para tal tarefa. A ideia básica é modelar um documento inteiro como um gráfico, onde os traços são representados por nós e conectados por arestas aos traços vizinhos.
Ao analisar o conteúdo de uma nota dessa forma, a GNN deve classificar todos os traços como texto ou não texto. Isso é feito analisando as características intrínsecas de cada traço e, quando necessário, considerando as informações contextuais fornecidas pelas arestas e pelos nós vizinhos de um traço.
Uma camada na GNN combina os recursos de um nó com os de seus vizinhos para produzir um vetor de valores numéricos representando recursos de nível superior. Assim como nas redes neurais convolucionais, várias camadas podem ser empilhadas para extrair um número crescente de recursos globais, permitindo assim uma decisão mais informada sobre se um traço constitui um traço de texto. Por exemplo, no diagrama a seguir, as duas linhas verticais mais à esquerda parecem semelhantes. Somente ao integrar informações contextuais de seus traços vizinhos é que a GNN pode classificar (na camada de saída) que o traço mais à esquerda faz parte de uma forma quadrada geométrica, enquanto o traço ao lado faz parte do caractere "T".
Aprendizado profundo e o modelo codificador-decodificador
Nem sempre é suficiente oferecer os dois melhores sistemas da categoria para reconhecer texto e matemática, principalmente para usuários que trabalham ou estudam em áreas científicas. Esses usuários geralmente precisam escrever a matemática como parte do texto corrente (não em um espaço separado da página) e esperam que o mecanismo de reconhecimento interprete ambos corretamente.
O desafio, então, era criar um sistema capaz de reconhecer caracteres e palavras misturados com expressões matemáticas, isto é, analisar uma combinação de uma linguagem natural unidimensional (texto) e uma linguagem bidimensional (matemática).
Com a onda do aprendizado profundo (deep learning), surgiram novas arquiteturas de redes neurais. Uma delas, o codificador-decodificador, tornou-se muito popular para resolver problemas de conversão seq2seq. Ele pode lidar com entradas e saídas de tamanho variável e se tornou o que há de mais avançado em campos próximos ao reconhecimento de texto escrito à mão, como reconhecimento de fala. A principal vantagem de um sistema codificador-decodificador é que todo o modelo é treinado de ponta a ponta, em vez de cada elemento ser treinado separadamente. Várias arquiteturas podem ser empregadas, incluindo camadas de rede neural convolucional, camadas de rede neural recorrente, unidades LSTM (long short-term memory, memória longa de curto prazo) e camadas baseadas em atenção, comumente usadas no modelo Transformer (para citar apenas algumas).
No nosso caso, a entrada do codificador-decodificador é uma sequência de coordenadas que representa a trajetória dos traços de caneta manuscritos. A saída é uma sequência de caracteres reconhecidos na forma de símbolos LaTeX (por exemplo, x^2 no lugar de x² ou (\frac{ }) no lugar de uma fração).


O futuro do texto escrito à mão de IA
A evolução da tecnologia de reconhecimento de texto escrito à mão está longe de terminar. Já estamos trabalhando para ampliar os recursos de nossa IA para que ela possa resolver problemas, incluindo a identificação automática de idioma e tabelas manuscritas interativas.
Acreditamos que os modelos de aprendizado profundo oferecem um enorme potencial de desenvolvimento e podem nos permitir unificar nossa abordagem a campos de pesquisa não relacionados anteriormente, como processamento de linguagem natural e análise de layout de documentos. Combinada com a crescente onipresença de dispositivos digitais habilitados para toque, estamos confiantes de que a IA nos permitirá passar de "reconhecer o que vemos" para "reconhecer o que foi intencionado". A diferença pode parecer sutil na página, mas na realidade isso representa mais uma mudança de paradigma. E estamos empenhados em ajudar a alcançá-lo.
Nossa visão é a de um mundo em que qualquer pessoa possa criar qualquer tipo de conteúdo no dispositivo da sua preferência tão livremente quanto em papel, mantendo todo o poder e a flexibilidade do digital. Graças ao poder da IA, essa visão se aproxima da realidade a cada dia.
