AI の重要性
AI とは「人工知能(artificial intelligence)」の略語です。 これは、人間の脳が持つ特定の機能(読む、理解する、分析するなど)を再現および強化できる、インテリジェントマシンの作成に関わるコンピューターサイエンスの分野を指します。
MyScript における AI とは
弊社のコアソフトウェア製品は、専有の AI テクノロジーを動力源としています。 弊社はこの AI を駆使して、70 種類以上の言語の手書きコンテンツを解釈し、手書きメモの構造を分析し、数式を理解し、手書きの楽譜を認識して変換しています。
弊社の技術は、20 年以上の研究開発に支えられています。 世界で最も精度の高い手書き認識エンジンを構築するために、言語形成の特徴について継続的なリサーチを実施しました(現在も継続中)。たとえば、単語から文章がどのように構築されるか、文字から単語がどのように構築されるか、また、発音区別符号が特定の母音の上または下にどのように配置されるかなどです。
MyScript では、いくつかの研究者グループが協力して、膨大な範囲の手書きコンテンツを理解できるクラス最高のシステムを開発および進化させています。
手書き研究
弊社の手書き研究チームは、機械学習技術を使用して、手書きテキストをその構成文字に変換する場合など、seq2seq(sequence-to-sequence)問題として定式化できる問題を解決しています。
たとえば、アラビア語やヘブライ語などの右から左へ書く言語、インド系文字の分音記号が付いた母音、漢字、韓国語のハングル文字、または日本語の縦書き(ひらがな、カタカナ、漢字)などを認識できるように、手法をさまざまなアルファベットや表記規則に適合させる必要があります。
2D 手書き研究
このチームは、二次元のパーサーや文法に基づいて数理モデルを構築しています。 そして、数式、楽譜、ダイヤグラムやチャートの認識など、seq2seq アプローチでは解決できない問題に対処しています。 このチームはグラフベースの手法を採用して認識を可能にしていますが、リアルタイムでの処理が大きな課題となっています。
自然言語処理研究
弊社の自然言語処理(NLP)チームは、人間と同じように言語を自然に理解できるアルゴリズムを開発しています。 このチームは、公開されている文書や記事から取得した数億もの単語を含むテキストコーパスを使用しています。 そこから、言語の語彙を構築したり、文章内の次の文字を予測するための精巧なモデルを構築したり、スペルミスを見つけて修正するシステムを設計したりしています。
データの収集
弊社の仕事の多くは、世界中のユーザーから自発的に送られてきた匿名のサンプルデータを基にしています。 これらの「トレーニングサンプル」(AI 研究で使われる用語)は、常にプライバシーとセキュリティに最大の配慮を払って扱われており、弊社にとっては大きな資産であるとともに、テクノロジーの改良や強化に役立っています。
手書き認識: 課題
手書き認識には、技術的に大きな課題があります。それは、手書きのスタイルに大きなばらつきがあるためです。 書く人の年齢、利き手、出身国、さらには手書き入力領域などの要因が、書こうとする文章に影響を与える可能性があります。これらは、さまざまな言語やアルファベットの影響を考慮する前の前提事項です。
これらの課題の例を挙げてみましょう。優れた手書き認識ソフトウェアでは、1 つの漢字を 30,000 を超える表意文字の中から区別できる必要があります。 また、双方向テキストを認識してデコードできる必要があります。これによって、右から左に書く言語(アラビア語やヘブライ語など)を使用するライターが、左から右に書く外国語を多数コンテンツ内に含める場合でも、ソフトウェアは動作を継続できます。
筆記体を手書きする場合は、ソフトウェアが個々の文字をセグメント化して認識するのがさらに難しくなります。また、遅延ストローク(発音区別符号など)があると、混乱する機会が増えます。 このようなメモに共通する非構造化レイアウトでは、コンテンツ分析を自動化することがはるかに難しくなります。数式、チャート、表など、他の種類のコンテンツを含める場合も同様です。
時間も要因の 1 つです。手書き認識ソフトウェアはリアルタイムで動作するものであり、ユーザーが書くと同時にその入力を解釈する必要があります。 ユーザーが書いている最中にコンテンツを編集する場合(たとえば、単語をスクラッチアウトして消去したり、スペースを挿入したり、段落を移動したりするなど)、認識エンジンはそれらの速さについていけなければなりません。
さらに、手書き認識技術は、ユーザーが Web ページや他のアプリからデジタルテキストをインポートし、必要に応じて手動で注釈を付けられるように、タイプセット文字や手書きのストロークを分析できる必要があります。 優れた認識エンジンは、このような複雑な相互作用を正確に解釈し、編集ジェスチャー、発音区別符号の付加、または新しい文字や単語の書き込みを区別しなければなりません。
ニューラルネットワークへの投資
20 年以上前、全世界の手書き認識研究コミュニティが隠れマルコフモデル(HMM)やサポートベクターマシン(SVM)に主力を注いでいたとき、MyScript は別の道を歩み始めました。
代わりに、ニューラルネットワークに焦点を当てたのです。
ニューラルネットワークは、人間の脳の学習プロセスを模倣する機械学習の一種です。 強力なアルゴリズムによって駆動するニューラルネットワークを使用すると、膨大なデータセットの中でパターンを識別できるため、弊社の研究つまり手書きについて、より正確な一般化が可能になります。
ニューラルネットワークは、既定の変数または「次元」に従ってパターンを識別するように「トレーニング」された数理モデルから構築されます。 慎重にプログラムされたアルゴリズムは、これらの次元に従ってデータを繰り返し分割およびソートし、明確なパターンが現れるまで分類と再分類を続けます。
このようにして、ニューラルネットワークは人間にはできないタスクを実行できます。 大量のデータを高速でふるいにかけ、見落としがちなパターンを強調します。 弊社は、ニューラルネットワークを使用して、過去に類を見ないほど正確で高度な手書き認識エンジンをトレーニングできると信じていました。
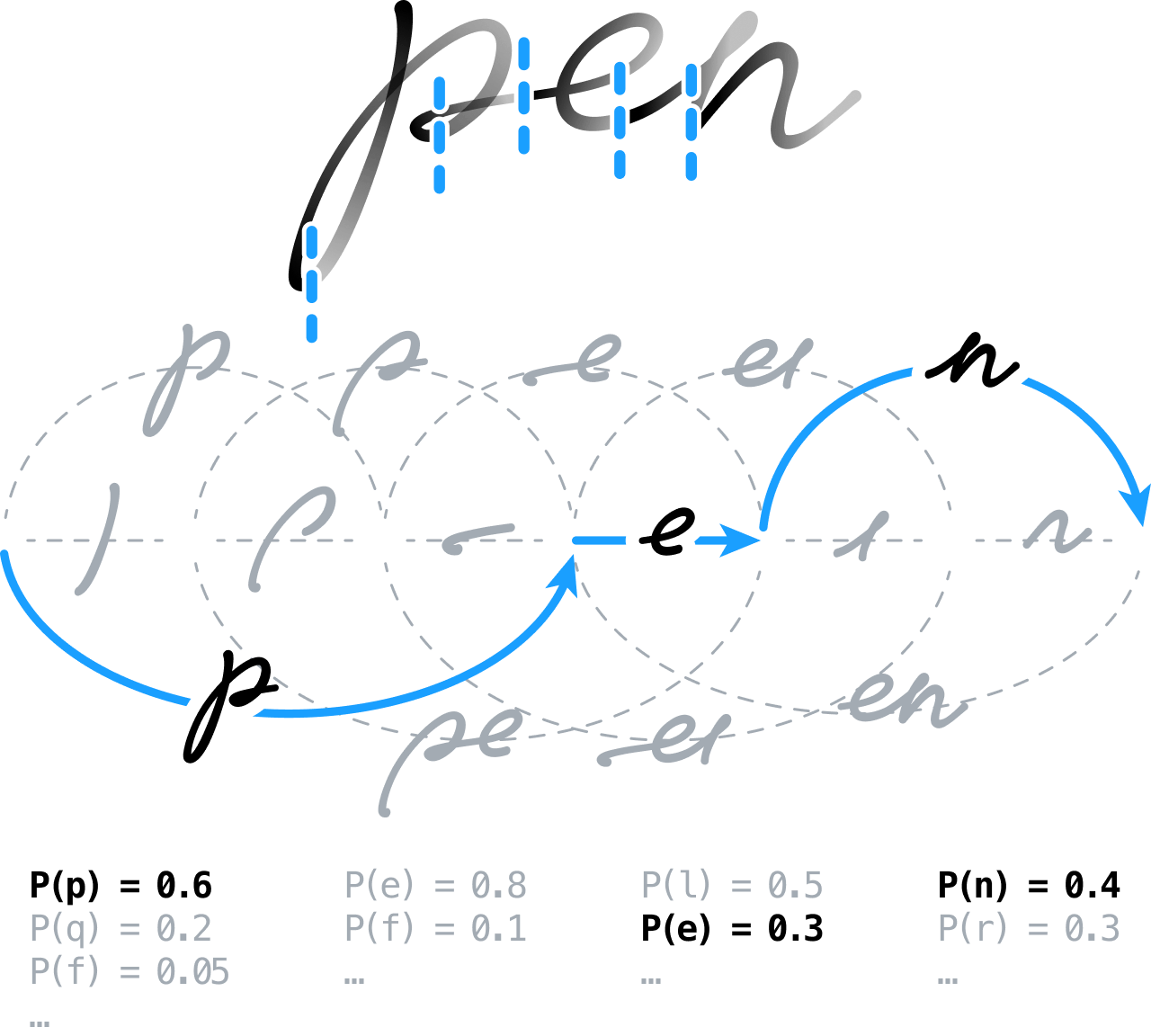
ニューラルネットワークを使用した手書き認識
当初、弊社のアイデアは、線の抽出、インクの正規化、傾きの修正などのタスクを実行することにより、手書きコンテンツを前処理して分析の準備を整えることでした。 そして、信号を大きめにセグメント化しておき、後で認識エンジンに文字と単語の境界の位置を決定させていたのです。
これは、可能なすべてのセグメント化をモデル化することによってセグメント化のグラフを構築することを意味していました。つまり、連続するセグメントを文字仮説にグループ化し、フィードフォワードニューラルネットワークを使って分類していたのです。 そこで、弊社はグローバルな識別トレーニングスキームに基づく新しいアプローチを採用しました。 現在、この手法は、コネクショニスト時系列分類(CTC)フレームワークで割と一般的に使用されており、seq2seq のニューラルシステムをトレーニングします。
また、弊社は、異なる文字候補間における残りのあいまいさのいくつかを明確にして解決するための、語彙・文法・意味的な情報を組み込んだ最先端の統計言語モデルを構築して採用しました。
2D 言語用の AI をトレーニング
ニューラルネットワークの成功により、弊社は活字体と筆記体の両方で世界最高の手書き認識エンジンを構築できました。 しかし、一部の言語はさらに複雑であり、それが次の課題となりました。
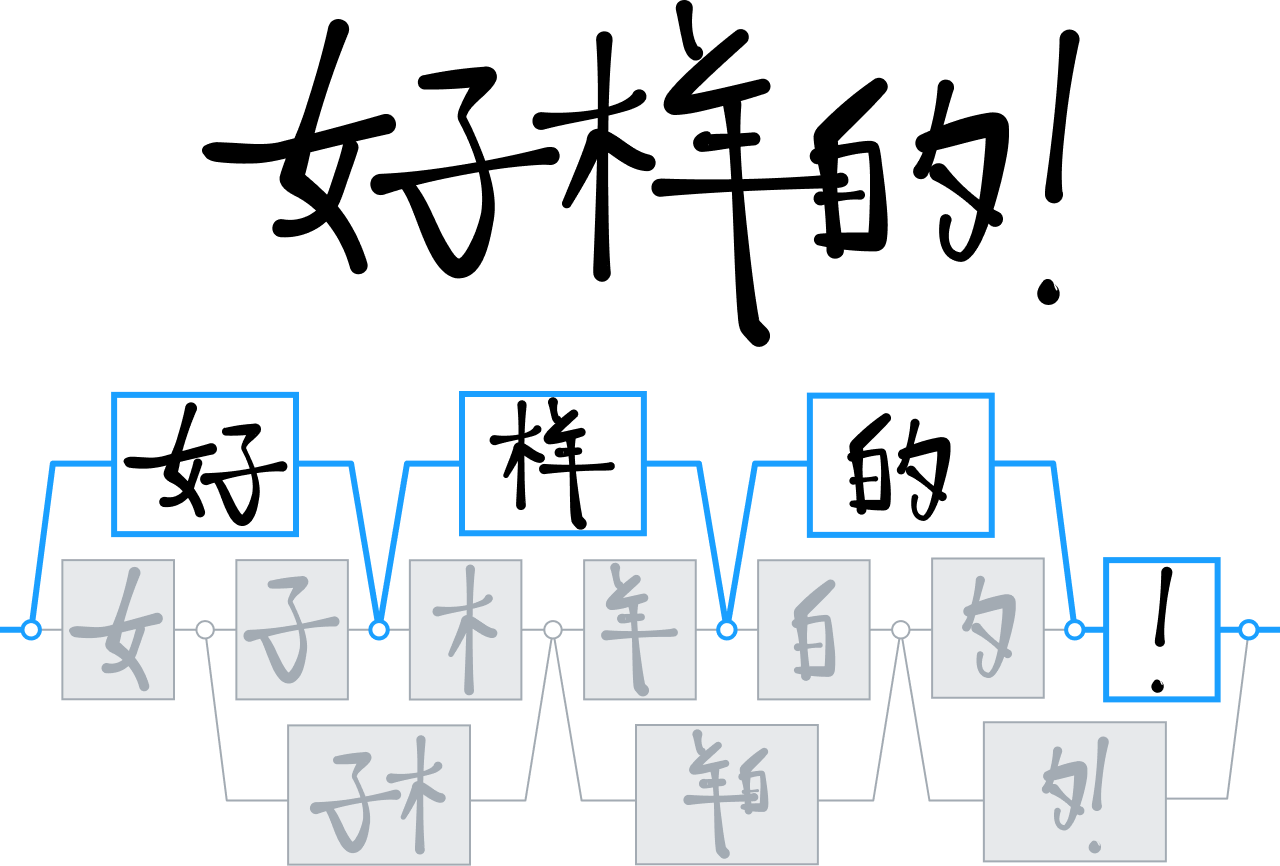
漢字の認識
MyScript は何年にもわたって、二次元言語、特に中国語の表意文字(漢字)を分析および解釈するためのさまざまなテクノロジーを開発してきました。
この分野のほとんどの競合他社は、決定木の手法を使用して漢字を区別および解釈していましたが、弊社はニューラルネットワークを 2 倍の規模にし、30,000 を超える表意文字を認識できるようにエンジンをトレーニングしました。
研究チームがこのような大規模なネットワークのトレーニングに成功したのは初めてでした。これは、大規模なデータ収集キャンペーンによって、過去に類を見ない最大の手書き漢字データセットを手に入れることができたからです。
弊社は、このデータを使用して、漢字の構造を利用した新しいニューラルアーキテクチャを開発したのです。また、処理時間を短縮するために、特殊なクラスタリング手法も統合しました。 これらのイノベーションにより、キーボード入力が困難で実現しにくいような市場に、新しいレベルの手書き認識を提供できるようになりました。 また、日本語、ヒンディー語、韓国語などの他の言語にも同等のサポートを追加することができました。
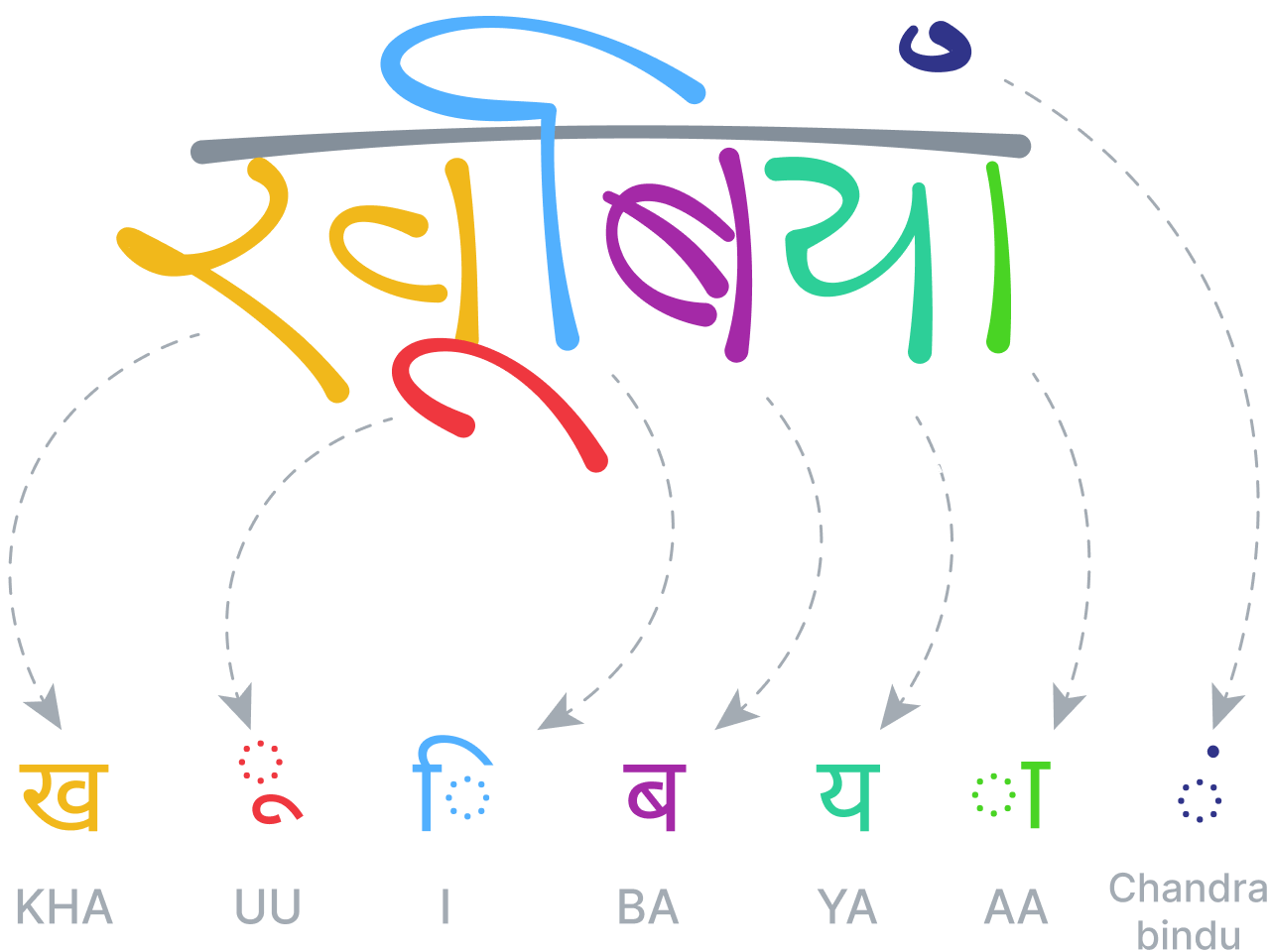
数式の認識
ニューラルネットワークを使用して世界のさまざまな言語を分析および認識できたことで、新しい目標が見えてきました。それは数式の認識です。
正規言語が文字と単語からなる構造シーケンスを持っているのに対し、二次元(または視覚)言語は、ノード間に空間的関係を持つツリーまたはグラフ構造によってより適切に説明できることがよくあります。 弊社の数式認識システムは、テキストの場合と同様、最良の認識候補を生成するために、セグメント化、認識、文法や意味の分析を同時に同じレベルで処理する必要があるという原則に基づいて構築されています。
このシステムは、特化された特定の文法に定められた規則に従って、数式のあらゆる部分における空間的関係を分析し、その分析を使用してセグメント化を決定します。 文法自体は、式の解析方法を説明する一連の規則で構成されており、各規則はそれぞれ特定の空間的関係に関連付けられています。 たとえば、分数規則は、分子、括線、および分母の間の垂直関係を定義するものです。
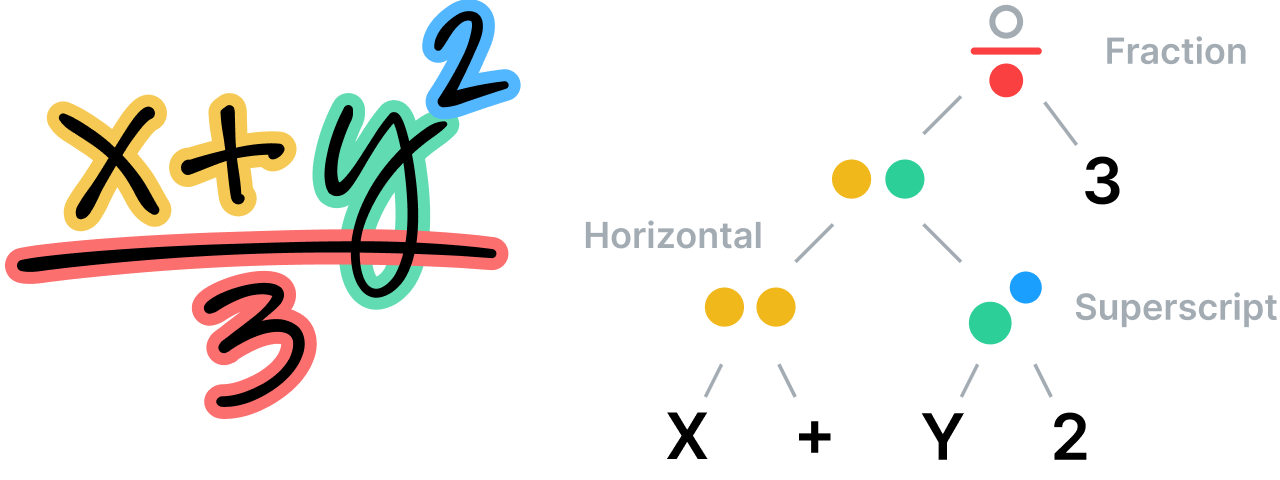
非構造メモの理解
数式をすばやく正確に認識することで、手書きメモのレイアウトとコンテンツに関連する新しい可能性が生まれました。
弊社の認識エンジンが数式の各部分間における空間的関係を正しく解釈できれば、テキスト以外のコンテンツも正確に識別できるかもしれないと考えたのです。 もしそうであるなら、弊社の技術を使用して、手描きのダイアグラムなどの要素を正確に識別し、さらには美化することで、構造化されていないメモが原因で発生する問題を排除していくことができます。
弊社は、このようなタスクにはグラフベースのニューラルネットワーク(GNN)アーキテクチャが適していると確信していました。 基本的には、文書全体をグラフとしてモデル化するという考え方です。ストロークはノードで表され、エッジによって隣接するストロークにつなげられます。
この方法でメモのコンテンツを分析する場合、GNN はすべてのストロークをテキストまたは非テキストとして分類する必要があります。 これは、各ストロークの固有のフィーチャーを分析し、必要に応じてストロークに隣接するエッジとノードによって提供されるコンテキスト情報を考慮することによって実現されます。
GNN 内の 1 つの層では、1 つのノードのフィーチャーが隣接するノードのフィーチャーと組み合わされて、より高いレベルのフィーチャーを表す数値のベクトルが生成されます。 畳み込みニューラルネットワークの場合と同様に、いくつかの層を積み重ねれば、さらに多くのグローバルフィーチャーを抽出できます。これにより、ストロークがテキストストロークを構成するかどうかに関して、より多くの情報に基づいた決定が可能となります。 たとえば、次のダイアグラムでは、左端の 2 本の垂直線は同じように見えます。GNN は、隣接するストロークからのコンテキスト情報を統合することによってのみ、左端のストロークが幾何学的な正方形の一部であり、その横のストロークは文字「T」の一部であるとして、それらのストロークを(出力層で)分類できます。
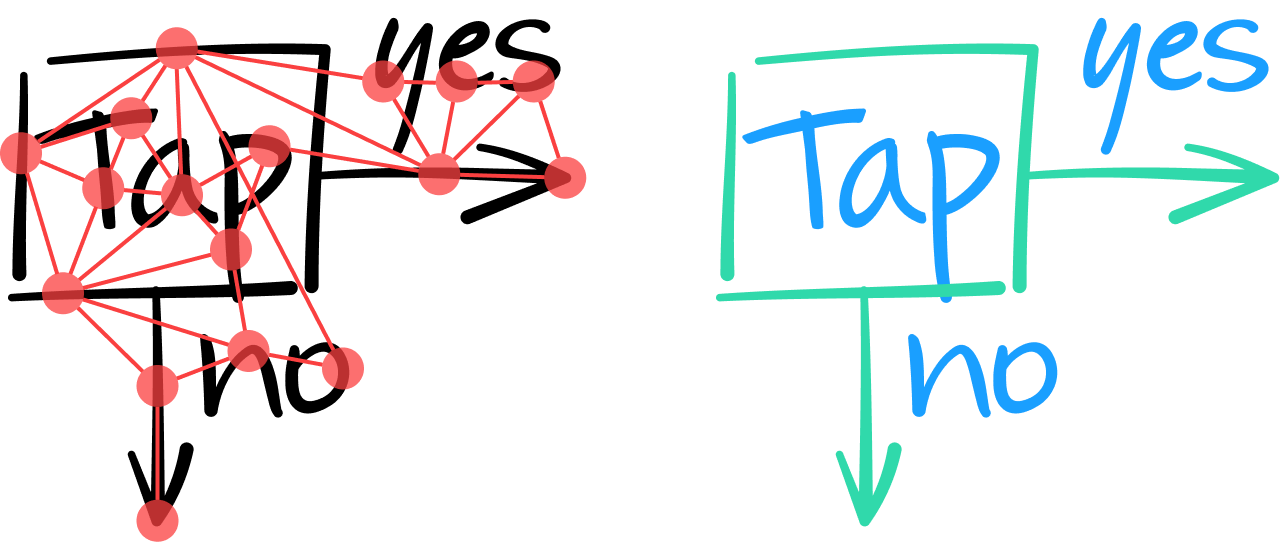
ディープラーニングと encoder-decoder モデル
テキストと数式を認識できる最高のシステムを 2 つ提供するだけでは十分でない場合もあります。特に科学分野で仕事または研究をしているユーザーにとってはそうです。 これらのユーザーは、書き込み中のテキストの一部として(ページ内の別のスペースではなく)インラインで数式を書き込むことがよくあるため、認識エンジンがそれらの両方を正しく解釈してくれることを期待しています。
したがって、数式が混在する文字や単語を認識できるシステムを設計することが課題でした。つまり、自然な一次元言語(テキスト)と二次元言語(数式)が組み合わさったものを分析することです。
ディープラーニングが普及してくるとともに、新しいニューラルネットワークアーキテクチャが登場しました。 そして、それらの 1 つである encoder-decoder が、seq2seq 変換問題を解決する手段として注目を浴びてきました。 可変長の入力と出力を処理できるため、最先端の手法として、音声認識などの手書き認識に近い分野で利用されるようになったのです。 encoder-decoder システムの主な利点は、各要素がそれぞれ個別にトレーニングされるのではなく、モデル全体がエンドツーエンドでトレーニングされることです。 例を挙げるとすれば、畳み込みニューラルネットワーク層、リカレントニューラルネットワーク層、LSTM ユニット(Long Short-Term Memory)、Transformer モデルでよく使用される注意ベースの層など、いくつかのアーキテクチャを採用できます。
弊社の場合、encoder-decoder の入力は、手書きのペンストロークの軌跡を表す一連の座標です。 出力は、LaTeX 記号で表される、認識された文字のシーケンスです(たとえば、x² の代わりに x^2、または分数の代わりに(\frac{ })。
AI を駆使した手書きの未来
手書き認識技術の進化はこれからも続きます。 弊社ではすでに、AI の機能を拡張して、言語の自動識別やインタラクティブな手書きの表などの問題を解決できるよう作業に取り組んでいます。
弊社は、ディープラーニングモデルが開発に大きな可能性をもたらすことを信じるとともに、自然言語処理や文書レイアウト分析など、以前は無関係だった研究分野へのアプローチも統合できるかもしれないと希望を抱いています。 また、タッチ対応のデジタルデバイスが普及するにつれ、AI によって「見えるものを認識する」から「意図されたものを認識する」に移行できると確信しています。 この違いはページ上では微妙かもしれません。しかし、実際にはこれは別のパラダイムシフトを表しています。そして、弊社はそれを実現するために日々努力をしています。
弊社のビジョンは、デジタルのフルパワーと柔軟性を維持しながらも、誰もが自分の好きなデバイスで、まるで紙面上に書くようにあらゆるタイプのコンテンツを自由に作成できる世界です。 AI のおかげで、そのビジョンは日々現実に近づいています。
