1/6/2026
Multilingual text recognition arrives in MyScript iink SDK 4.3

MyScript iink SDK 4.3 marks an important step in how we approach handwriting intelligence for text. With this release, we introduce a new handwriting recognition engine for Latin scripts that is multilingual by design.
Instead of treating languages as separate configurations, the new engine recognizes multiple languages within the same note, using a single, smaller resource. The result is a simpler user experience, easier integration for developers, and solid performance improvements across a wide range of use cases.
A simpler way to handle languages
With the new engine, content is no longer tied to a single recognition language. The model can recognize 7 Latin languages simultaneously:
- English (US and UK)
- Spanish (ES and MX)
- French
- Portuguese
- German
- Italian
- Dutch
This means a page can start in French and continue in Spanish without requiring any change in settings. For users, especially in shared environments, this removes a familiar friction point. In classrooms, for example, a student moving from a maths lesson in French to a language class in Spanish no longer needs to adjust recognition preferences between sessions.
For OEMs and application developers, this flexibility translates directly into a cleaner product experience. Fewer language selectors, fewer configuration edge cases, and fewer opportunities for users to get stuck with the wrong setting. Language handling becomes something the engine manages quietly in the background.
Accuracy gains from a unified handwriting model
The new encoder-decoder architecture based on attention replaces a collection of language-specific experts with a single neural network trained across all supported languages. This significantly simplifies how the system is built, deployed, and maintained. Its higher learning capacity enables the unified model to learn more effectively from large, diverse handwriting datasets and adapt to varied writing styles and languages without hand-tuned rules for each language.
In practice, this architectural shift preserves overall recognition quality while delivering tangible improvements. Across our internal benchmarks on large note-taking datasets collected under real-world conditions, we achieve consistent accuracy across supported languages and regional variants. For English in particular, the new engine shows 20% fewer recognition errors compared to the previous approach.

One multilingual resource
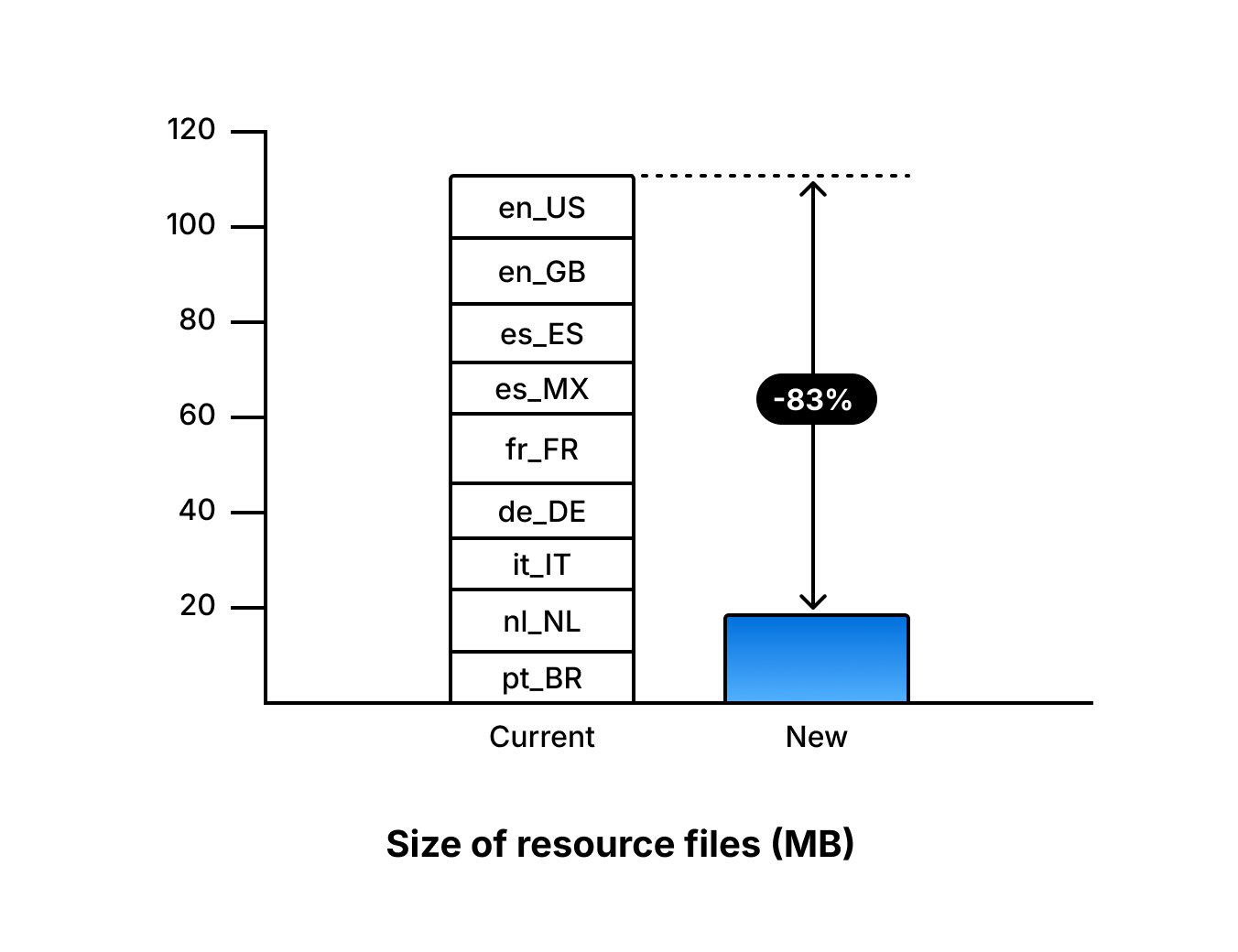
In earlier versions of the text engine, each language typically relied on seperate language resources. These included an alphabet knowledge (AK) to model characters and a linguistic knowledge (LK) for word context.
When supporting multiple languages, this quickly added up: several files per language, along with the code needed to select, download, and keep them in sync.
The new engine replaces this stack with a single multilingual text resource covering 7 Latin languages. Instead of managing dozens of files, developers now bundle one resource of about 18 MB. Previously, the equivalent language resources alone required slightly more than 100 MB, representing an 83% reduction in size.
Faster batch recognition
For applications that rely on the raw content recognizer in batch recognition rather than processing ink incrementally, the new architecture also delivers meaningful performance gains.
On average, processing time is reduced by about 30%. This makes large imports, document migrations, and indexing tasks faster and more predictable.
Other changes
The Eraser tool now responds to pen pressure, allowing the eraser size to adjust dynamically for a more natural erasing experience.
Shape‑on‑hold handling in Raw Content parts has been simplified by a new method invoked on shape‑on‑hold actions, returning the associated strokes, action type, and the recognized shape in Jiix.
Moving towards a unified model
We believe the gains in simplicity, developer experience, and performance make this new engine the natural choice for text recognition, especially in new projects.
We continue to support integrations relying on customization controls like subset knowledge resources, custom lexicons, or text recognition candidates. For these use cases, the legacy engine remains available and fully supported.
Looking ahead, our work focuses on widening and unifying this approach. We are extending multilingual support to additional Latin languages, while in parallel developing a dedicated resource for CJK scripts. Combined with our existing math and shape recognition engines, these efforts move us closer to a unified handwriting intelligence model that handles text, mathematics, and shapes consistently across languages.
For a detailed list of API changes, please refer to the iink SDK 4.3 changelog in the docs. If you would like to discuss how this release fits into your product roadmap, our team is available to help. Feedback on accuracy, language coverage, and missing capabilities will directly influence what we build next.